Neon is a single writer, multiple readers, and multi-tenant system that runs in Kubernetes containers. The two cornerstones of Neon’s architecture are:
- separation of compute and storage, and
- non-overwriting storage.
In a previous article, I talked about architectural decisions and the reasons behind them. In this article, we take a closer look at the storage engine.
Separation of Compute and Storage
Traditionally, databases like PostgreSQL have a single instance controlling the storage on a single node. This can be a local SSD, an EBS volume on the cloud, or something else. However, this setup becomes complex as you introduce backups, log streaming, and replicas.
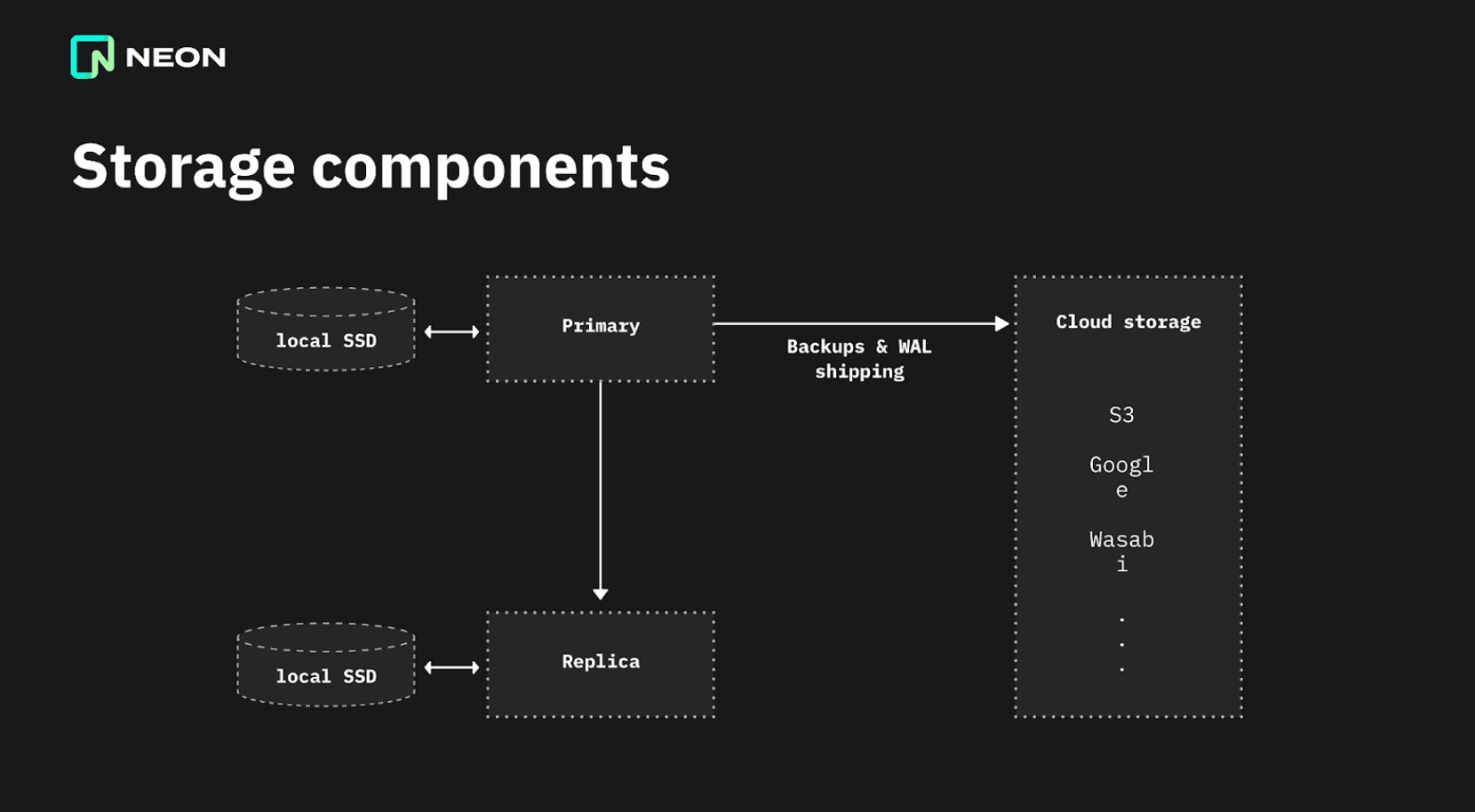
Neon splits up the system so that only one copy of your database is needed, and it lives in the Neon storage engine. This single storage system can serve the primary, and as many read-only nodes as you want. It also acts as an archive and natively supports time-travel queries and branches, which makes traditional WAL shipping and backups unnecessary. This simplifies the setup quite a lot because now you only have one storage system to worry about.
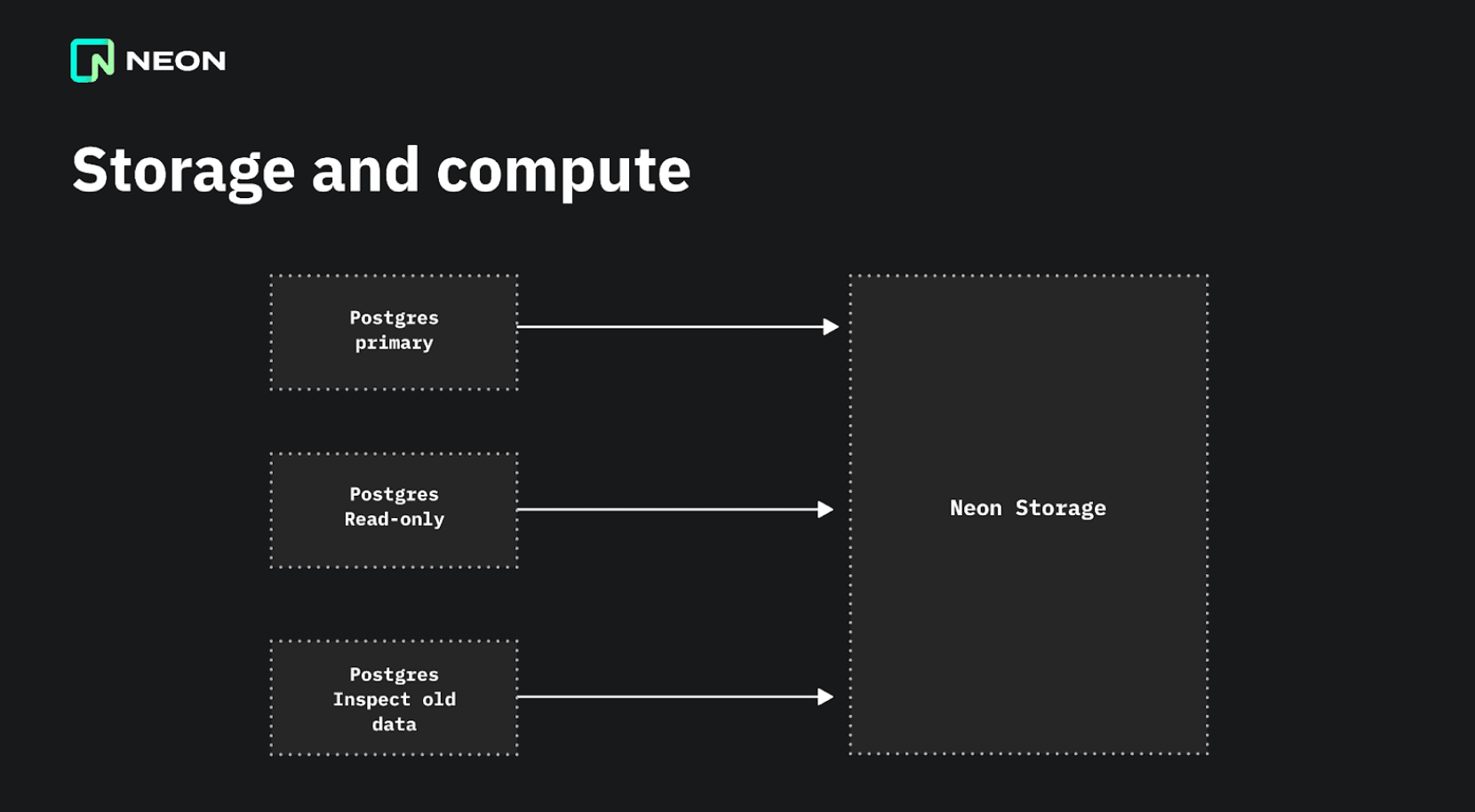
By separating compute and storage, Neon can be serverless. When a database is inactive for more than five minutes, it is shut down, and the compute node is removed. When you connect to it again, a new compute node is spun up in a Kubernetes container. This is quick because it doesn’t need to restore the data; it only needs to connect to the existing storage system.
The separation of compute and storage also allows for independent scaling. You can add as many read-only nodes as you need and scale out the storage system independently of the compute nodes. The storage is integrated with cloud storage like Amazon S3 or Google Cloud Storage, uploading and downloading files from the cloud storage as needed.
Storage Engine: Under the Hood
Internally, the storage engine is modeled as a key-value store. The key is composed of the relation-id and block number. The value is an 8KB page or a write-ahead-log (WAL) record. There is also metadata to track the sizes of tables and indexes.
The storage engine is inspired by and shares some similarities with Log-Structured Merge (LSM) trees:
- Just like LSM trees, the storage is non-overwriting. Files are created and deleted, but they are never updated in place. Immutable files are important to integrate with cloud storage, such as S3, which don’t allow random updates.
- The incoming WAL stream is first buffered and organized in memory. When 1GB of WAL has accumulated, it is written out to a new layer file.
- Old files are merged and compacted by creating new files and deleting old ones.
Despite the similarities, we could not find an LSM tree implementation that fit our needs directly. The main differences are:
- Neon also needs to access the history, not just the latest version of each value, to allow for point-in-time recovery and branching. Many LSM implementations support snapshots, which allow you to see old versions, but snapshots are assumed to be short-lived. They are not designed to keep the history around for weeks or months.
- The storage engine uploads all files to cloud storage, and downloads them back on demand.
- As we will see in the later section on non-overwriting storage, we have two kinds of values: image and deltas.
Let’s first look at the write path and the read path:
Write path
In the write path, PostgreSQL writes a record to the transaction log (write-ahead log) whenever a modification is made. In Neon, this log is streamed to three safekeeper nodes, which provide durability and synchronous replication using Paxos-like consensus algorithm that was explained in a previous article.
The safekeeper nodes then stream the logs to the pageservers, where the logs are processed, reorganized, and written to immutable files. Finally, these files are uploaded to cloud storage for long-term storage.
Cloud storage is useful because it offers virtually bottomless storage, so you never run out of disk space. Read I/O and caching can be scaled by scaling out the pageservers.
The non-overwriting storage format makes it easy to support copy-on-write branching. When a new branch is created, the branch is empty at first, but the incoming WAL on the branch is stored separately from the parent branch. If you access a part of the database that hasn’t been modified on the branch, the storage system fetches the data from the parent branch instead.
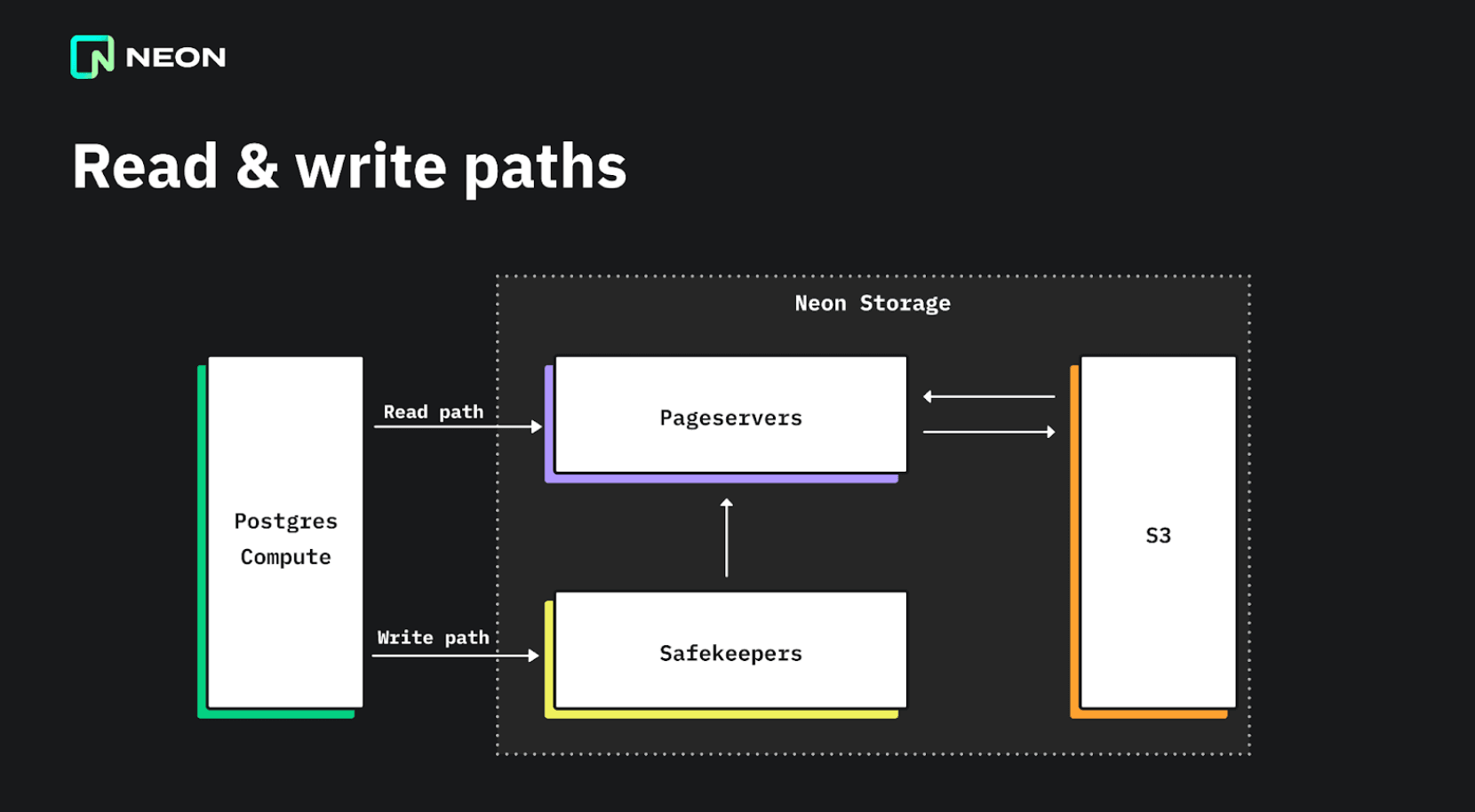
Read path
The read path in the storage system allows immediate access to the most recent data, but also to historical versions of the data, without traditional backups. Every read request from a compute node to the pageserver includes a log sequence number (LSN), and the pageserver returns the data as it was at the requested LSN.
When a read request comes in, the pageserver finds the last image of the page by the LSN, and any write-ahead-log (WAL) records on top of it, applies the WAL records if needed to reconstruct the page, and returns the materialized page to the caller. We call this function GetPage@LSN.
The LSN is a monotonically increasing integer that identifies a particular WAL record. It can be thought of as a point in time in the database history – when you perform Point-in-Time Restore, what you really restore to is a particular LSN. The pageserver retains all the WAL in a randomly-accessible format, so it can reconstruct pages as of any LSN, allowing for time travel queries. Primary nodes always request the latest version of each page. However, you can also create a node or a branch at an older LSN, to see the data as it was at that point in time.
Non-Overwriting Storage
The second cornerstone of the Neon storage system is the non-overwriting storage format. This allows Neon to replace traditional backups and work seamlessly with older versions of data.
Neon eliminates the distinction between active data and backups, treating all data the same in the storage system. Because old data is not modified, whenever new data is digested into the system, all the history stays accessible up to a configurable limit.
The storage system processes incoming WAL logs, reorganizes them, and writes it out to layer files. The non-overwriting storage is a good fit for cloud storage, as cloud storage doesn’t allow for random updates or reads.
Layer Files and Non-Overwriting Storage
As new data is added to the system, it is organized into layer files. We have two types of layers: delta and image layers.
- Image layer contains a snapshot of all key-value pairs in a key-range at one LSN
- Delta layer contains all changes in a key and LSN range. If a key wasn’t modified, it’s not stored. Incoming WAL is written out as delta layers.
Image layers are created in the background to speed up access and to allow garbage collecting old data.
To reconstruct a page version, GetPage@LSN needs to find the latest image of the page, at or before the requested LSN, and all the WAL records on top of it. The search starts at the given block number and LSN, and walks through the layers collecting the WAL records for the page. The search stops when an image of the page is found.
To ensure that the search for any particular page doesn’t take too long, the delta and image layers are reshuffled through compaction operations in the background. And eventually, when they are no longer needed, they are garbage collected.
The below application illustrates how the storage system manages layer files over time. The workload is pgbench, which is a simple OLTP benchmark tool that comes with PostgreSQL. The X axis represents the key space, and the Y axis represents LSN. We can see three types of objects:
- Delta layers (gray rectangles)
- Image layers (purple lines)
- Garbage collection horizon (orange line)
The purple horizontal lines represent image layers. The pgbench benchmark has one append-only table called “history”. You can see a “gap” in the X-axis for that portion of the keyspace, where the delta layers get garbage collected away, and the system keeps only the latest image layers. Suppose you have a cold table or portion of the database, like the “history” table. In that case, the storage system eventually reaches a stable state for that portion where only a set of old image layers is retained.
Conclusion
Neon decouples storage and compute, and introduces a new way of thinking about storage. Traditional installations require planning for the primary disk size, number of replicas, backup cadence and retention size and WAL archiving, and time required to restore from backup.
With Neon, you don’t need to think about those things anymore. Instead, you think in terms of a retention period and branches.