Despite the fact that Postgres has been around for almost 30 years, Neon has always been an innovative company supporting experimental ideas. So, obviously, we couldn’t miss the AI fever. 🙂
We started our first experiments with AI a little more than a year ago, but only recently have we focused on bringing AI-driven features into our product. Let’s take a look at them, and later discuss how we implemented them.
AI features in our SQL editor
We are happy to bring you our first AI features that will empower the SQL playground experience. They work in tandem to assist with SQL writing.
SQL generation
This has got to be the most exciting and complex feature. By pressing the ✨ button or using Cmd/Ctrl+Shift+M, can enter a natural language prompt describing the SQL you want to execute, and Neon will generate the query text for you. After that, you can change the generated query as you like or just execute it as is.
If you are not sure whether the generated query is safe to run towards your actual database, you can simply create a branch and run it there. To make the generation sensible, we extract your database schema and pass it to the LLM along with the prompt. So, if you ask to find data that is not present in the database, you are expected to get a descriptive error response.
This feature heavily relies on LLM capabilities, so we tried multiple models (more about that in the next section), and none of them were perfect. So it’s possible that a generated query will not work exactly as you expect, that’s why, for now, we’ve stopped at the generation, and we leave the execution to users.
Query name generation
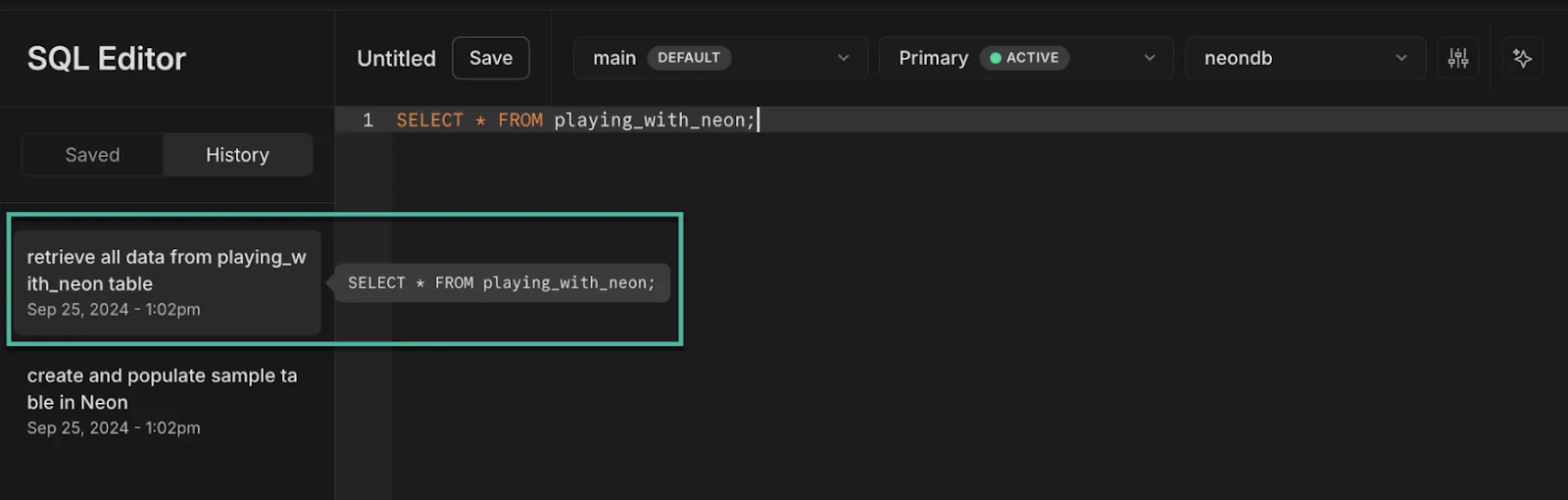
A second feature: Now, the query history block will contain meaningful names for your queries. We take the executed query and generate a name for it by asking the LLM model to predict the best-fitting name.
Error fixing
It’s common to make a typo or confuse some parts of your database when you write a complex query. Or maybe you have a wider park of different databases and don’t exactly remember all Postgres operators and functions. So, in some cases, the execution may result in an error.
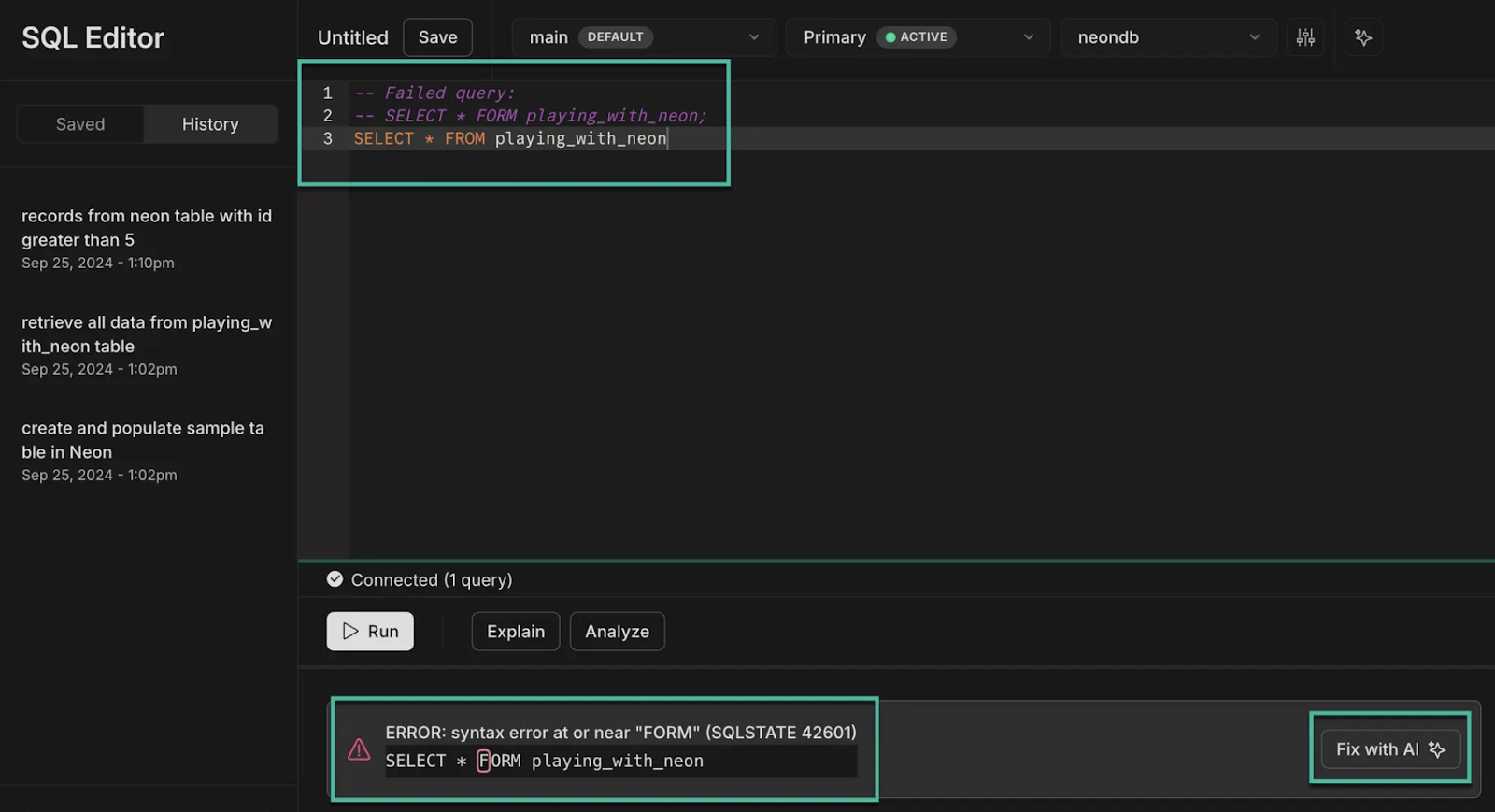
Now, we provide a single button that will take your query and Postgres errors, pass it to the LLM and ask it to fix the query. After that, we will stream the fixed query into the editor box. This can work nicely along the SQL generation: if the generated SQL contains some errors, this step can potentially fix them. This feature also adds the database schema to the request context.
Why not an AI assistant?
For users that are already familiar with AI-driven features in similar products, it may seem unnatural that we didn’t choose the “AI assistant” path – this is, a sidebar with a chat where you can ask questions and get answers.
There are two main reasons for this decision:
- It’s complex to make it useful. If you are chatting with an assistant bot, you expect it to understand your questions and the current context well. So, if you are asking about the current query, it should understand that and take it into consideration. If you are referencing some table, it should query the database scheme and use that information. To achieve this, the process ideally should be multi-stage: the first steps should help figure out the context, and the last steps would prompt actual results, with an optional follow-up to refine the answer. This is a lot of engineering effort.
- Tailored experience. If we choose the path of an AI assistant we would have much less control over the user experience, basically it narrows down to a simple dialog and set of predefined actions. With our current solution, we provide actionable elements next to their respective contexts, which improves user comfort and boosts discoverability. Also, it’s much easier to do experiments or debugging this way.
TIL building AI features – or what did I carry as a valuable experience
Don’t make a guessing choice
If you’ve listened to some of Uncle Bob’s rants, you may favor this idea: if you don’t know what to choose – don’t, until you do know. So, I didn’t know which model would perform best, so I chose a good old strategy pattern. It’s actually very simple and comfortable to implement in any language with interfaces, like typescript, go, java, etc. Here is how it looks in our typescript code:
export interface AIPrompter {
prompt(
/* user prompt */
message: string,
/* system prompt */
system: string,
): Promise<() => AsyncGenerator<string>>;
}So, currently, our strategy code should implement a single prompt method, which can be provided by almost any model and provider. Based on certain conditions we could pick a concrete implementation of this interface like OpenAIGpt4o or AWSBedrockClaude3_5. After getting some working code to our production under a feature flag we would conduct several experiments with different providers.
For now, we’ve stopped on Claude 3.5 Sonnet by Anthropic. But we can easily swap it for some other AWS Bedrock or OpenAI-provided model.
Infra for AI
There are several types of AI providers and options out there. The first two categories I want to touch are self-hosted and API providers.
It is no secret that hosting a decently performing model costs a lot. So, unless you expect a pretty significant traffic, it’s better to avoid this route. In my opinion, it starts to pay off on a pretty large scale.
Out of API providers, I highlight two groups:
- Cloud infrastructure integrated providers like AWS Bedrock, Azure AI Services, GCP AI and ML services.
- AI-specializing companies providers like OpenAI, Anthropic, Groq, Meta AI, etc.
If you are doing a smaller project or experiment, then going to direct AI providers would probably be the best option. Most of them are easy to set up, they have simple, convenient APIs, usage tracking and budget limiting.
If you are a bigger company or a cloud company and most parts of your system are already hosted in some cloud provider like AWS, Azure, GCP, etc., then consider using their solutions since they are better tied to your existing infrastructure and you can extend your existing infra to provide role access, budgeting, logging, usage tracking.
The biggest downside is that you are limited by whatever your cloud provider gives you. For example, you won’t be able to use GPT models in AWS Bedrock. Also, in our case, we need to share the user’s database schema with an AI provider, so we would need a separate user’s consent to do that unless we are using Bedrock, which resides in AWS, the same place we store the user data in.
HTTP can stream
Most of the AI providers support streaming response. So, a question arises: how do you stream that response to a browser? With the arrival of WebSockets, it’s easy to forget, but the HTTP response can be streamed! So you don’t really need anything special to return a streaming response from your API.
Example in node js:
async function performResponse(response: http.ServerResponse, aiStream: Stream) {
response.writeHead(200);
for await (const message of aiStream) {
const { usage, choices } = message;
const [choice] = choices;
if (choice?.delta?.content) {
response.write(choice.delta.content);
}
}
response.end();
}Now in the frontend code we can use Fetch API to receive the stream:
const { body } = await fetch('/api/ai');
const reader = body.getReader();
while (true) {
const chunk = await reader.read();
if (chunk.value) {
// ... do something with the streamed response
}
if (chunk.done) {
break;
}
}Wrap up
If you are a Neon user, I encourage you to try out these new features and tell us how they work for you!
If you are a developer, I hope these ideas can be useful for your own projects. You should definitely be enthusiastic about trying out LLMs to boost your product: it’s simple and cheap enough to experiment with.