Point In Time Recovery Under the Hood in Serverless Postgres
Disaster recovery and Time Travel queries in Neon Postgres

We are Neon, the serverless Postgres. We separate storage and compute, allowing developers to query their database at any point in its history. In this article, Raouf explains how Neon’s storage system enables Time Travel queries to confidently run your Point In Time Restore processes.
Imagine working on a crucial project when suddenly, due to an unexpected event, you lose significant chunks of your database. Whether it’s a human error, a malicious attack, or a software bug, data loss is a nightmare scenario. But fear not! We recently added support for Point-In-Time Restore (PITR) to Neon, so you can turn back the clock to a happier moment before things went south.
You can try PITR on Neon for free now.
In the video below and in the PITR announcement article, my friend Evan shows you can recover your data in a few clicks. He also uses Time Travel Assist to observe the state of the database at a given timestamp to confidently and safely run the restore process.
How is this possible? This article is for those interested in understanding how PITR works under the hood in Neon. To better explain this, we will:
- Cover the basics of PITR in Postgres
- Explore the underlying infrastructure that allows for PITR in Neon.
We’ll ensure by the end of this post that you’re always prepared for disaster strikes.
Understanding the basics of Point In-Time Recovery in Postgres
PITR in Postgres is made possible using two key components:
- Write-Ahead Logging: Postgres uses Write-Ahead Logging (WAL) to record all changes made to the database. Think of WAL as the database’s diary, keeping track of every detail of its day-to-day activities.
- Base backups: Base backups are snapshots of your database at a particular moment in time.
With these two elements combined, you define a strategy to restore your database to any point after the base backup was taken, effectively traveling through your database’s timeline. However, you’d need to do some groundwork, which consists of the following:
- Setting up WAL archiving: By defining an `archive_command` and setting `archive_mode` to `on` in your `postgresql.conf`.
- Creating base backups: You can use the `pg_basebackup` to create daily backups.

If, for any reason, you need to restore your database, you need to recover the latest backup and replay the WAL on top of it. The same logic applies to restoring from a point in time in the retention period.
Let’s say we want to restore the database to its state on February 1st at 14:30. We first locate the last backup file created before that target time, restore it, and then replay the WAL up to that time.

Great! We now know how to perform a PITR in Postgres. However, there are a few limitations to this approach:
- You might notice a drop in performance while performing backups,
- Because you have a finite storage capacity, you must define a limit to your archived WAL. This limit is known as the retention period (a.k.a history retention), which determines how far back in time your data can be restored.
- You have a single point of failure (SPOF) since all base backups and WAL archives are in the same location.
We can enhance our architecture by adopting disaster recovery tools like Barman to avoid SPOF and downtime. With Barman, Postgres streams base backups and WAL archives to an external backup server. Or, if you know what you’re doing, you can configure Postgres to stream base backups and WAL archives to an AWS S3 bucket, and add a standby, which serves as an exact copy of your database, to avoid downtime. Your setup would look like this:

To sum it up and to perform a PITR in Postgres without downtime, you need to:
- Have a backup server
- Set up WAL archiving and stream it to the backup
- Schedule daily backups
Additionally, you need to install a bunch of packages and configure and maintain this infrastructure, a time that can be spent focused on your application instead. It’s that convenience, simplicity, and confidence in your data of use that Neon offers.
So, how do we make it look so easy? Let’s step back and explain how Neon’s storage engine works.
Understanding Neon’s architecture
Neon’s philosophy is that the “database is its logs”. In our case: “Postgres is its WAL records”.
Neon configures Postgres to stream the WAL to a custom Rust-based storage engine. Neon’s storage engine is composed of three parts:
- A persistence layer called “Safekeepers” makes sure the written data is never lost, using Paxos as a consensus algorithm.
- A storage layer called “Pageservers”: multi-tenant storage that can reconstruct the data from WAL and send it to Postgres.
- A second persistence layer to durably store the WAL in AWS S3.
And since all the data is stored in Neon’s storage engine, Postgres doesn’t need to persist data on the local disk. This turns Postgres into a stateless compute instance that can start in under 500ms, making Neon serverless.
As a result, we no longer require:
- A standby: because, in the case of a Postgres crash, we can quickly spin up another instance.
- Backups: Neon’s storage engine stores the WAL and creates and performs compactions
The data flow would look like the following:

Check out the Architecture decisions in Neon article by Heikki Linnakangas to learn more.
To understand the magic behind PITR in Neon, we’ll explore how the Pageservers work.
Pageservers: under the hood
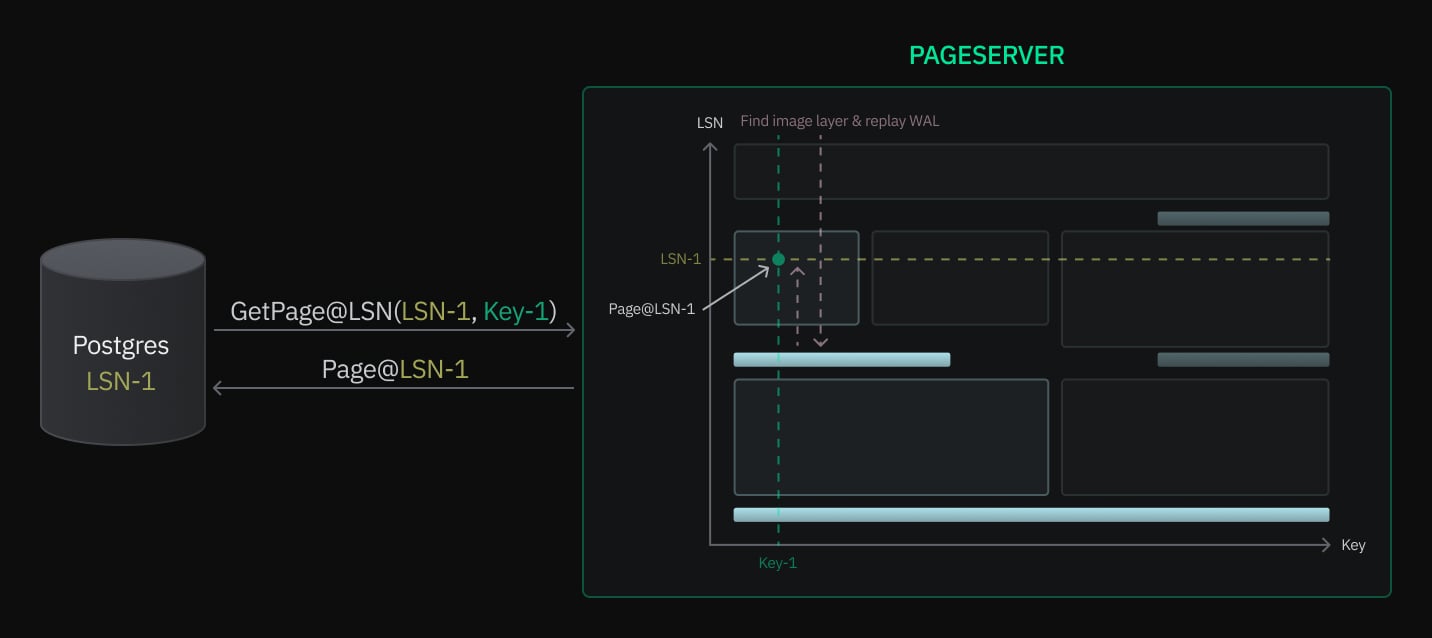
Each transaction in the WAL is associated with a Log Sequence Number (LSN), marking the byte position in the WAL stream where the record of that transaction starts. If we follow our initial analogy of WAL being a detailed diary of everything in the database, then the LSN is the page number in that diary.
The Pageserver can be represented by a 2-dimensional graph, where the Y-axis is the `LSN`, and the X-axis is the `key` that points to the database, relation, and then block number. A key for example can point to certain rows in your database.

When data is written in Neon, the role of Pageservers is to accumulate WAL records. Then, when these records reach approximately 1GB in size, Pageservers create two types of immutable layer files:
- Image layers (bars): contain a snapshot of a key range for a specific LSN. You can see Image Layers as the state of rows in certain tables or indexes at a given time.
- Delta layers (rectangles): contain the incremental changes within a key range. You can see Delta layers as a log of all the changes that happened to your rows.
Does this sound familiar?
Indeed, it employs the same principle as the traditional Postgres setups for PITR we’ve previously discussed, which include base backups and WAL archiving. The main difference here is that you don’t need to initiate a lengthy and complex restore procedure every time you wish to read data from a previous state of the database. This is because Pageservers inherently know how to reconstruct the state of the page at any given LSN or timeline.
Ephemeral branches
We mentioned previously that, in Postgres, each WAL record is associated with an LSN. In Neon, Postgres tracks the last evicted LSN in the buffer cache, so Postgres knows at which point in time it should fetch the data.
When Postgres requests a page from the Pageserver, it triggers the GetPage@LSN function, which returns the state of a given key at that specific LSN.
Read the Deep dive in Neon’s storage engine article to learn more about Neon’s architecture.
In practice, you can access different timelines through database branches. These branches are copy-on-write clones of your database, representing the state of your data at any point in its history. When you create a branch, you specify the LSN (or a timestamp), and Neon’s control plane generates a timeline associated with your project, keeping track of it.
We’ve enhanced the Point In Time Recovery (PITR) feature in Neon with Time Travel Assist. This functionality allows you to perform Time Travel queries to review the state of your database at a specific timestamp or LSN, following the same underlying steps:
- Creating a timeline, and
- Running GetPage@LSN.
However, these branches are ephemeral, having a Time To Live (TTL) of 10 seconds. We refer to these as ephemeral branches, and they will soon become a crucial part of your development workflows.
Ephemeral branches enable you to connect to a previous state of your database by merely specifying the LSN or timestamp in your connection string. This capability is natively supported by Pageservers, and Neon’s PITR feature is the first step towards making ephemeral connections available to developers. Stay tuned for more development in this area.
Conclusion
While Postgres’ features offer powerful options and tools like Barman to help with disaster recovery, Neon’s approach makes PITR reliable, accessible, efficient, and integrated into a seamless database management experience.
By first exploring how to do PITR in Postgres, we’ve learned about the importance of continuous archiving and creating base backups.
Neon’s storage engine saves WAL records and snapshots of your database and can natively reconstruct data for any point in time in your history. This capability allows for the Time Travel Assist to query your database at a given timestamp before you proceed to its restoration using short-lived or ephemeral branches.
Ephemeral branches introduce a unique way to interact with your data’s history by allowing developers to access different timelines and perform Time Travel queries to provide the ability to review prior states and understand your data’s lifecycle.
What about you? How often do you use PITR in your projects? Join us on Discord and let us know how we can enhance your Postgres experience in the cloud.
Special thanks to skeptrune for reviewing and suggesting adding a mention to Barman.